Tóm tắt
Theo cách truyền thống, dữ liệu nghiên cứu và ấn phẩm khoa học thường được lưu trong các hệ thống quản lý tách biệt nhau. Điều này dẫn đến một tình huống bất lợi đối với nhà nghiên cứu khi họ cần phải sử dụng những hệ thống khác nhau để tìm thấy thông tin thích hợp về một chủ đề nghiên cứu nào đó. Bởi vậy, chúng ta thường gặp phải một thách thức khi trung hoà sự tách biệt giữa hệ thống biểu ghi thư mục và dữ liệu nghiên cứu bằng việc cung cấp một môi trường tìm kiếm tích hợp cho cả ấn phẩm và dữ liệu nghiên cứu. Chính bởi vì tồn tại một cấu trúc hệ thống khác biệt nhau, không có tính gắn kết, cũng như siêu dữ liệu mô tả ấn phẩm và dữ liệu nghiên cứu thường khác nhau. Một dạng dữ liệu của một hệ thống quản lý thông tin này không dễ gì tích hợp vào một hệ thống thông tin được thiết kế cho một dạng dữ liệu khác. Chúng tôi đã nhận ra những thách thức phát sinh khi làm cho hệ thống mục lục thư viện thích nghi với dữ liệu nghiên cứu và đưa ra được các gợi ý cho triển khai tích hợp hiệu quả. Bằng việc trình bày một phương pháp mẫu, chúng tôi cho thấy thư viện hoàn toàn có khả năng ứng dụng và thực hành đối với giải pháp Primo, một giải pháp được đưa vào dự án để tiến hành nghiên cứu này.
Vì những tính năng trong mô hình mục lục thư viện mẫu đưa vào nghiên cứu của chúng tôi cho phép nối kết giữa các ấn phẩm và các bộ dữ liệu nghiên cứu nằm bên dưới, bởi vậy chúng tôi cung cấp một truy cập trực tiếp tới siêu dữ liệu nghiên cứu lưu trong các kho dữ liệu nghiên cứu ở xa và kết nối cả hai dạng dữ liệu từ các hệ thống quản lý thông tin khác nhau.
Giới thiệu
Trong lĩnh vực khoa học xã hội và những lĩnh vực nghiên cứu thực nghiệm khác, dữ liệu gốc từ các cuộc điều tra, phỏng vấn và nghiên cứu liên quan thường là cơ sở cho nhiều ấn phẩm khoa học được xuất bản sau này, và cũng là cơ sở cho các quy trình nghiên cứu kế tiếp. Do có những tiến bộ trong công nghệ, dữ liệu nghiên cứu giờ đây có thể được xuất bản dưới hình thức điện tử. Điều này đang làm đơn giản hoá đáng kể khả năng truy cập tới dữ liệu này và tạo ra một cơ hội cho việc xử lý lặp lại bằng các phương tiện của công nghệ máy tính hiện đại. Hiện nay, dữ liệu nghiên cứu gốc và ấn phẩm khoa học được lưu trữ trong các hệ thống quản lý riêng rẽ, nhưng lại có cấu trúc. Trong khi các thư viện phần lớn tập trung vào quản lý ấn phẩm đã xuất bản, thì các tổ chức nghiên cứu lại tập trung vào quản lý dữ liệu nghiên cứu hay quy trình tạo ra dữ liệu nghiên cứu.
Tìm kiếm đối với các kết nối kết giữa dữ liệu nghiên cứu gốc và những phát hiện công bố trong các ấn phẩm khoa học chắc rằng sẽ rất phức tạp và tốn nhiều thời gian. Để có thể tìm thấy ngay một tham khảo ẩn giấu bên trong hoặc được chỉ dẫn ra bên ngoài hướng tới dữ liệu nghiên cứu, nhà nghiên cứu thường phải đọc toàn bộ qua nhiều ấn phẩm. Sau đó, họ phải tìm kiếm trong các kho số dữ liệu nghiên cứu chuyên biệt nhằm tìm thấy thông tin về bộ dữ liệu nghiên cứu đó. Quy trình kéo dài này làm giảm khả năng kiểm chứng những phát hiện trong nghiên cứu cũng như việc sử dụng lại dữ liệu cho tham khảo thêm khó khăn. Trong dự án “InFoLiS” (Integration of Research Data and Literature in the Social Sciences), một dự án được quản lý bởi viện GESIS (Leibniz-Institute for the Social Sciences) ở Đức, Thư viện Đại học Mannheim (The Mannheim Univeristy Library) và Đại học Mannheim (Mannheim University) đối mặt với một thách thức làm thế nào để trung hoà được sự khác biệt giữa biểu ghi thư mục và dữ liệu nghiên cứu bằng việc thiết lập các nối kết giữa các dạng dữ liệu khác nhau và tích hợp chúng vào trong các hệ thống thông tin khác nhau.
Trong bài báo này, chúng tôi tập trung vào tích hợp dữ liệu nghiên cứu và nối kết dữ liệu nghiên cứu vào trong các mục lục thư viện. Để thực hiện nghiên cứu này, chúng tôi sử dụng mục lục của Thư viện Đại học Mannheim, một mục lục được triển khai trên hệ thống phát hiện và chuyển giao tài nguyên thông tin tập trung và thống nhất “Primo”, một giải pháp phát triển bởi Ex Libris. Lý do chúng tôi chọnPrimo đó là hiện Primo đang được sử dụng bởi một cộng đồng người dùng thư viện lớn nhất hiện nay, bao gồm nhiều thư viện đại học và nghiên cứu hàng đầu trên thế giới,đồng thời giải pháp này có đủ bộ ánh xạ dữ liệu thích hợp nhất để triển khai nghiên cứu này. Chúng tôi lấy dữ liệu nghiên cứu từ kho số của uỷ ban đăng ký dữ liệu xã hội và kinh tế “da|ra” (Registration Agency for Social and Economic Data). Ví các mục lục thư viện thường được chuyên biệt hoá trong việc trình bày siêu dữ liệu đối với các ấn phẩm, cho nên chúng tôi đã tiến hành nhiều phương pháp phù hợp hoá dữ liệu với mục đích tích hợp được siêu dữ liệu của bộ dữ liệu nghiên cứu vào mục lục thư viện:
1. Chúng tôi phải trích xuất dữ liệu nghiên cứu
2. Chuyển đổi chúng tới các định dạng thích hợp và
3. Tải vào trong hệ thống cùng với nối kết giữa các dữ liệu nghiên cứu và các ấn phẩm khoa học.
Ở phần sau, chúng tôi cũng giới thiệu phương pháp nối kết giữa dữ liệu nghiên cứu và các ấn phẩm khoa học và đưa ra khả năng tích hợp. Cuối cùng, chúng tôi đi đến kết luận với những gợi ý về triển khai kỹ thuật và mô tả trải nghiệm người dùng tin mà chúng tôi có được. Có một thuận lợi là chúng tôi đã sử dụng các giao diện ánh xạ sẵn có trong Primo vì nó được xử lý hoàn toàn bởi hệ thống Primo.
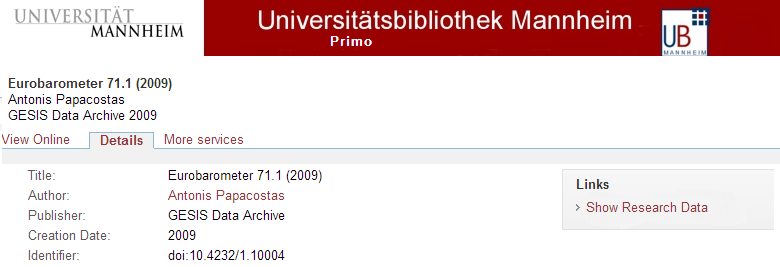
HÌNH 1. Tích hợp Siêu dữ liệu Nghiên cứu trong Primo
HÌNH 1 cho thấy một ví dụ của biểu ghi siêu dữ liệu nghiên cứu được tích hợp vào trong Primo. Ngoài thông tin về nhan đề, tác giả v.…v, nó cũng bao gồm một nối kết tới chính bộ dữ liệu nghiên cứu gốc có thể cung cấp nội dung nghiên cứu. Bằng việc nhấp chuột vào nối kết “Show Research Data”, một DOI (Digital Object Identifier) sẽ được xử lý bởi hệ thống và người dùng tin được đưa đến tài nguyên nghiên cứu phù hợp.
Nối kết giữa dữ liệu nghiên cứu và ấn phẩm khoa học
Vì nối kết giữa dữ liệu nghiên cứu và ấn phẩm hiếm khi được biện tập vào siêu dữ liệu mô tả ấn phẩm hoặc dữ liệu nghiên cứu, bởi vậy đây là bước đầu tiên để nhận ra những nối kết như vậy. Để triển khai thử nghiệm này, chúng tôi sử dụng nhiều phương pháp nghiên cứu tiếp cận đặt ra trong dự án InFoLiS. Theo những phương pháp mẫu của dự án, chúng tôi nối kết ấn phẩm chứa đựng trong kho số truy cập mở về khoa học xã hội “SSOAR” (Social Science Open Access Repository) tới dữ liệu nghiên cứu nằm trong kho dữ liệu nghiên cứu da|ra và ngược lại. Chúng tôi chọn kho số SSOAR bởi vì nó chứa một khối lượng lớn dữ toàn văn các ấn phẩm khoa học truy cập mở, miễn phí, song điều này không có nghĩa là phương pháp kết nối của chúng tôi chỉ làm việc với dữ liệu cụ thể của kho số này. Vì mục lục thư viện Đại học Mannheim phần lớn chỉ trình bày những ấn phẩm xuất bản là sách và bộ sưu tập, bởi vậy chúng tôi đã tạo ra nhiều biểu ghi cho tất cả ấn phẩm trong kho số SSOAR ở cấp độ bài báo nghiên cứu. Về nguyên tắc, nối kết giữa dữ liệu nghiên cứu và bộ sưu tập cũng được thiết lập, song chúng tôi đã xem xét nhiền nối kết phù hợp hơn để nó hữu ích hơn với người dùng tin. Khi hệ thống nhận ra một nối kết phù hợp, những nối kết đó sẽ được tích hợp vào hệ thống và người dùng tin có thể thấy nói theo nhiều cách khác nhau.
Phát sinh nối kết giữa dữ liệu nối kết giữa dữ liệu nghiên cứu và ấn phẩm khoa học
Nối kết giữa ấn phẩm và các bộ dữ liệu nghiên cứu được tự động sinh ra bằng việc sử dụng cách tiếp kiểm tra lặp lại những tham khảo liên quan đến các bộ dữ liệu nghiên cứu nằm trong các ấn phẩm khoa học. Dự án bắt đầu với tên của một nghiên cứu, đó là “seed”, và tìm kiếm từ khoá này cùng với trích xuất các ngữ cảnh liên quan, ví dụ các từ với các ký tự xuất hiện xung quanh từ này. Sau đó, nó tiếp tục tìm những ngữ cảnh khác của các từ này để tìm thấy thêm các từ liên quan trong nghiên cứu. Thuật toán được triển khai sẽ dừng lại nếu hệ thống không tìm thấy một ngữ cảnh và từ mới nào liên quan đến nghiên cứu nữa. Kết quả là một danh mục tên từ khoá nằm trong nghiên cứu được tham khảo cho mỗi ấn phẩm được trả về. Để tóm tắt quá trình thử nghiệm này, thuật toán đã học được các mẫu dữ liệu đặc thù cho những tài liệu tham khảo đối với dữ liệu nghiên cứu, mà sau đó mẫu dữ liệu đó được sử dụng để nhận ra các tham khảo liên quan trong văn bản ẩn chứa bên trong một tên miền chuyển giao dữ liệu.
Sau khi áp dụng thuật toán này, những tên từ khoá được nhận ra trong nghiên cứu cần được ánh xạ tới mục thuộc tính trong một kho số chứa đựng bộ dữ liệu nghiên cứu. Hay nói cách khác, những nối kết chỉ tham khảo tới tên bộ dữ liệu nghiên cứu chứ không phải chính bộ dữ liệu nghiên cứu. Trong khi thuật toán này được phát triển để nhận ra tên của một nghiên cứu, thì thông tin về năm, phiên bản, mô tả số liệu phải được trích xuất từ một chuỗi tham chiếu (reference string) ở một bước riêng rẽ. Cùng với nhan đề nghiên cứu, thông tin này sẽ được sử dụng để tìm kiếm những nghiên cứu tương ứng và chỉ số DOIs trong khó số quản lý dữ liệu nghiên cứu da|ra.
Đối với các ấn phẩm, một URN (Universal Resource Name) được trích xuất từ siêu dữ liệu củaSSOAR đóng vai trò như một điểm nhận biết cho dạng dữ liệu này. Đối với phương pháp thực hành mẫu trình bày trong bài báo này, chúng tôi sử dụng một tập tin dữ liệu nối kết phát sinh ra và được kiểm tra thủ công bằng tay. Nó được lưu trong một tệp tin .CSV đơn giản để xử lý tiếp.
Tích hợp các nối kết giữa dữ liệu nghiên cứu và các ần phẩm khoa học
Khi tích hợp các nối kết vào hệ thống thông tin Primo, tối thiểu sẽ có hai cách: tải các nối kết trực tiếp vào hệ thống sử dụng các bộ làm giàu dữ liệu trên máy chủ, hoặc hiển thị các nối kết mà không cần lưu chúng trên máy chủ sử dụng các bộ làm giàu dữ liệu phía máy khách.
Phương pháp làm giàu dữ liệu thông quan máy chủ: Phụ thuộc vào kỹ thuật tích hợp siêu dữ liệu mô tả các bộ dữ liệu nghiên cứu, một số cách có thể được triển khai để tải các nối kết vào bên trong hệ thống. Nếu siêu dữ liệu được sử dụng hình thức trích xuất từ cơ sở dữ liệu, các nối kết có thể dễ dàng được thêm vào trước khi tải biểu ghi vào bên trong Primo. Với cách này, nối kết chỉ là một phần tử thông tin khác trong siêu dữ liệu. Khi tích hợp bằng sử dụng các giao thức vận hành liên kết được thực hiện, chúng tôi không thêm trực tiếp thông tin gì nữa. Tuy nhiên, chúng tôi có thể sự dụng các bộ chương trình làm giàu dữ liệu sẵn có trong Primo để đưa vào các nối kết này. Các bộ chương trình làm giàu dữ liệu của Primo là các ứng dụng viết trên Java có thể xử lý các biểu ghi phù hợp hoá dữ liêu biểu ghi PNX (Primo Normalized XML). Biểu ghi này có thể được điểu chỉnh phù hợp, vì dụ trường dữ liệu có thể được thêm/loại bỏ/thay đổi, trước khi biểu ghi được lưu vào trong cơ sở dữ liệu của hệ thống. Tất cả những sửa đổi này có thể được thực hiện bằng việc sử dụng nhiều trình API XML đơn giản sẵn có trong Primo. Để làm giàu siêu dữ liêu với nối kết, các ứng dụng làm giàu dữ liệu sẽ kiểm tra xem liệu một DOI/URN phù hợp có một mục từ trong tệp tin nối kết hay không. Nếu có, nối kết đó sẽ được được lồng vào trong biểu ghi và lưu nó lên cơ sở dữ liệu. Trong quá trình triển khai dự án nghiên cứu này, chúng tôi đã triển khai nhiều chức năng như vậy để làm giàu thêm cho các biểu ghi thu hoạch được.
Phương pháp làm giàu dữ liệu thông qua máy khách: Thậm chí không cần có một dữ liệu bổ sung nào được tải vào bên trong một hệ thống thông tin, nhưng các nối kết có thể vẫn được hiển thị tới người dùng tin một cách thích hợp. Trong trường hợp này, một giải pháp can thiệp tối thiểu sẽ được áp dụng triển khai, ví dụ, bằng sử dụng các bộ “Plugin API” được phát triển cho Primo tại Thư viện Đại học Mannheim. Với API này, chúng tôi có thể thêm vào thông tin làm giàu thư mục, ví dụ như một nối kết tới một dữ liệu nghiên cứu liên quan thông qua JavaScript. Bởi vậy, tệp tin nối kết cần được xác định trong một máy chủ mà ở đó thông tin có thể được tiếp cận thường xuyên.
Tương tự như tích hợp siêu dữ liệu mô tả dữ liệu nghiên cứu, khi mà một bộ làm giàu dữ liệu phía máy chủ cần triển khai một số cơ chế cập nhật phù hợp, thì bộ làm giàu dữ liệu phía máy khách luôn hiển thị một nối kết cập nhật nhất vì nó chỉ được tích hợp khi chương trình đang chạy theo thời gian thực. Vì chúng tôi muốn tải siêu dữ liệu mô tả bộ dữ liệu nghiên cứu này vào trong hệ thống nhằm cho phép nó có thể tìm kiếm được chúng thông qua mục lục thư viện, bởi vậy chúng tôi chọn sử dụng các bộ làm giàu dữ liệu từ phía máy chủ cho mục đích nghiên cứu này. Dù sao, việc trình bày các nối kết giữa hai phương pháp hoàn toàn giống nhau. Một ví dụ được mô tả ở Hình 2 dưới đây khi có một kết nối mở rộng trỏ tới dữ liệu nghiên cứu liên quan cho một ấn phẩm/tài liệu tìm thấy trong mục lục thư viện.

HÌNH 2: Tích hợp Dữ liệu Nghiên cứu được nối kết trong Primo
Kết luận
Chúng tôi đã trình bày cách tiếp cận tới việc tích hợp siêu dữ liệu mô tả dữ liệu nghiên cứu và nối kết giữa dữ liệu nghiên cứu các ấn phẩm khoa học vào các mục lục thư viện, ví dụ bằng sử dụng giải pháp Primo. Chúng tôi đã mô tả những thách thức khi triển khai tích hợp giữa các hệ thống thông tin thư mục với các dạng dữ liệu nghiên cứu khác biệt. Một nhiệm vụ được thực hiện đó là ánh xạ bộ từ vựng siêu dữ liệu mô tả bộ dữ liệu nghiên cứu sao cho có sự tương thích giữa hai hệ thống thông tin khác nhau. Nếu siêu dữ liệu nào phù hợp cho mô tả dữ liệu nghiên cứu được đưa thêm vào, nhưng không mô tả ấn phẩm, thì triển khai này đòi hỏi phải định nghĩa các trường siêu dữ liệu tuỳ biến hoặc tận dụng các trường siêu dữ liệu hiện có và định hướng có chủ định cho sử dụng. Sau quá trình chuyển đổi, siêu dữ liệu có thể được tích hợp vào mục lục thư viện. Tuy nhiên, việc ánh xạ dữ liệu luôn gắn với từng kho số hoặc tên miền cụ thể, và nó thường không thể được sử dụng lại khi tích hợp các nguồn dữ liệu khác nhau. Ngoài ra, chúng tôi cũng triển khai một số cơ chế cập nhật giúp cho dữ liệu tích hợp luôn mới và chính xác. Thay vì tích hợp siêu dữ liệu mô tả dữ liệu nghiên cứu sử dụng biện pháp trích xuất dữ liệu, chúng tôi có thể sử dụng thu hoạch dữ liệu thông qua các giao thức vận hành liên kết tiêu chuẩn nếu chúng sẵn có. Bởi vậy, sau đó dữ liệu đã được trình bày theo khổ mẫu tiêu chuẩn hoá như DC (Dublin Core) và toàn bộ quá trình tích hợp này diễn ra trong chính hệ thống quản lý thông tin. Cuối cùng, chúng tôi đã xem xét sâu đối với việc tạo ra và tích hợp quy trình nối kết giữa dữ liệu nghiên cứu và các ấn phẩm khoa học. Chúng tôi triển khai một bộ làm giàu dữ liệu phía máy chủ để tích hợp nối kết vào bên trong hệ thống bằng việc tận dụng nhiều bộ làm giàu hiệu quả từ giải pháp Primo. Nhìn chung, chúng tôi đã đưa ra một phương pháp làm việc mẫu dựa trên những gợi ý cho phép tích hợp siêu dữ liệu mô tả dữ liệu nghiên cứu và nối kết hiệu quả vào trong các mục lục thư viện. Như một phần của công việc nghiên cứu tiếp theo, chúng tôi sẽ tiến hành nghiên cứu người dùng tin để đánh giá xem sự làm giàu dữ liệu thư mục có hữu ích cho việc tìm thấy tài liệu và các bộ dữ liệu nghiên cứu phù hợp cho nhiệm vụ nghiên cứu trong lĩnh vực khoa học xã hội hay không.
Tài liệu tham khảo
1. Boland, Katarina, Dominique Ritze, Kai Eckert, and Brigitte Mathiak. (2012). Identifying References to Datasets in Publications. Proceedings of the Second International Conference on Theory and Practice of Digital Libraries, 2012,150-161.
2. ExLibris. (2013). Back Office Guide Version 4.x. Retrieved March, 28, 2013.39
3.Proceedings of International Conference on Dublin Core and Metadata Applications 2013
4.Hausstein, Brigitte, Nicole Quitzsch, Kirsten Jeude, Natalija Schleinstein, and Wolfgang Zenk-Möltgen. (2013). da|ra Metadaten Schema Version 2.2.1. GESIS Technical Reports.
5.Ritze, Dominique, and Kai Eckert. (2012). Data Enrichment in Discovery Systems using Linked Data. Proceedings of the 36th Annual Conference of the German Classification Society, 2012, to be published.
Biên tập và tổng hợp theo công bố nghiên cứu của nhóm dự án InFoLIS